在开始讲这些问题之前,需要先阅读完以下文档:
《优化网站的抓取与收录》 http://www.google.cn/ggblog/googlewebmaster-cn/2009/08/blog-post.html
《谷歌搜索引擎入门指南》第7页到11页。 点此下载
《创建方便 Google 处理的网址结构》 http://www.google.com/support/webmasters/bin/answer.py?hl=cn&answer=76329
这些都是google官方的文档,讲述了各种各样的规则。这些对百度也是同样适用的,因为它是针对爬虫的特性提出来的,并不是只有某个搜索引擎才适用。
看完上面的那些这些规则,发现翻来覆去讲得都是怎么让爬虫能非常顺畅的抓取完整个网站。其实绝大部分网站都存在这样或那样的问题的,也包括我这个博客,在抓取方面也存在一些问题。但是看在每篇博文都能被收录的情况下,也就不去优化了。但是对于很多收录还成问题的网站(特别是大中型网站)来说,就要好好规划一下了。大家可以用HTTrack抓取semyj这个博客看看,就能发现为什么我这么说了。(谁能一天之内抓取完这个博客的人请告诉我。)
还是先从搜索引擎的处境讲起吧。正如Google在文章中写道的那样:
网络世界极其庞大;每时每刻都在产生新的内容。Google 本身的资源是有限的,当面对几近无穷无尽的网络内容的时候,Googlebot 只能找到和抓取其中一定比例的内容。然后,在我们已经抓取到的内容中,我们也只能索引其中的一部分。
URLs 就像网站和搜索引擎抓取工具之间的桥梁: 为了能够抓取到您网站的内容,抓取工具需要能够找到并跨越这些桥梁(也就是找到并抓取您的URLs)。
这段话很好的总结了搜索引擎所面临的处境,那么爬虫在处理URL的时候会遇到哪些问题呢?
我们先来看重复URL的问题,这里说的重复URL是指同一个网站内的不同页面,都存在很多完全相同的URL。如:
http://www.semyj.com/archives/1097 和 http://www.semyj.com/archives/1114 这两个页面。
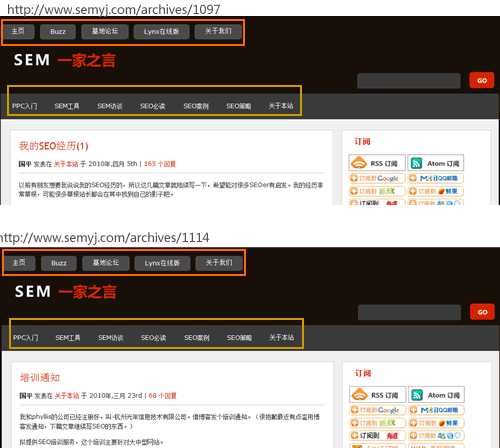
模板部分的URL是一样的
虽然页面不同,但是他们公用的部分,URL地址是一样的。看起来如果不同的爬虫抓取到这些页面的时候,会重复抓取,从而浪费很多不必要的时间。 这确实是一个问题,不过这个问题搜索引擎倒是基本解决好了。实际上,爬虫的抓取模式不是像我们理解的那样看到一个网页就开始抓取一个网页的。
爬虫顺着一个个的URL在互联网上抓取网页,它一边下载这个网页,一边在提取这个网页中的链接。假设从搜索引擎某一个节点出来的爬虫有爬虫A、爬虫B、爬虫C,当它们到达semyj这个网站的时候,每个爬虫都会抓取到很多URL,然后他们都会把那个页面上所有的链接都放在一个公用的“待抓取列表”里。(可以用lynx在线版模拟一下爬虫提取链接。)
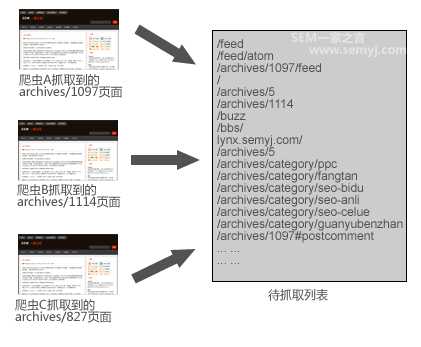
待抓取列表
这样一来,在“待抓取列表”里,那些重复的URL就可以被去重了。这是一个节点在一种理想状态下的情况,不过实际上因为搜索引擎以后还要更新这个网页等等一些原因,一个网站每天还是有很多重复抓取。所以在以前的文章中,我告诉大家用一些方法减少重复抓取的几率。
这里有一个问题,很多人肯定想问是不是一个网页上所有的链接搜索引擎都会提取的,答案是肯定的。但是在《google网站质量指南》中,有这样一句:“如果站点地图上的链接超过 100 个,则需要将站点地图拆分为多个网页。”有些人把这句话理解为:“爬虫只能抓取前100个链接”,这是不对的。
因为在“待抓取列表”里的URL,爬虫并不会每一个链接都会抓取的。 链接放在这个列表里是没问题的,但是爬虫没有那么多时间也没必要每个链接都要去抓取,需要有一定的优先级。在“待访问列表”里,爬虫一边按照优先级抓取一部分的URL,一边把还未被抓取的URL记录下来等待下次抓取,只是这些还未被抓取的URL,下次爬虫来访问的频率就每个网站都不一样了, 每一类URL被访问的频率也不一样。
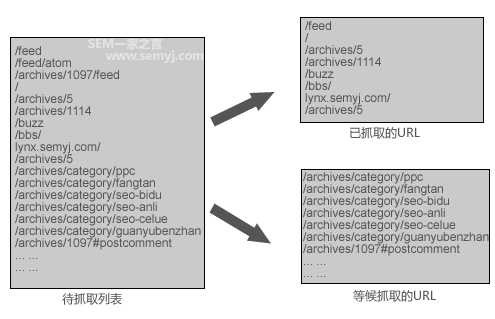
按优先级抓取
那么在“待抓取列表”里的URL,哪些是能被优先抓取,哪些是被次要抓取的呢?
我们稍微思考一下都能明白这个抓取的优先级策略应该怎么定。首先,那些目录层级比较深的URL是次要抓取的;那些在模板部分的或重复率非常高的URL是被次要抓取的;那些动态参数多的URL是次要抓取的…。.
这么做的原因,就是因为搜索引擎的资源是有限的,一个网站实际拥有的内容也是有限的,但是URL数量是无限的。爬虫需要一些“蛛丝马迹”来确定哪些值得优先抓取,哪些不值得。
在《谷歌搜索引擎入门指南》中,google建议要优化好网站的URL结构,如建议不要用“…/dir1/dir2/dir3/dir4/dir5/dir6/page.html”这样的多层嵌套。就是因为在待抓取列表里,在其他条件相同的情况下,爬虫会优先抓取目录层级浅的URL。如用Lynx在线版查看本网站的页面:
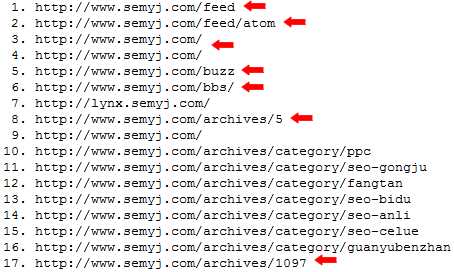
抓取优先级
如果说,在这17个链接里,爬虫只能选几个链接抓取的话,红色箭头所指的链接在其他条件相同的情况下是要优先的。
但是这里又有一个误区,有人在SEO过程中,把所有的网页都建立在根目录下,以为这样能有排名的优势。这样也是没有理解这个原因。而且爬虫在这个网站上先抓取哪些URL后抓取哪些URL,都是自己的URL和自己的URL比,如果所有网页都是在同一个目录下,那就没有区别了。
最好的规划URL目录层级的方式,就是按照业务方的逻辑来规划,从内容上应该是什么从属关系就怎么规划URL就是。就像《谷歌搜索引擎入门指南》中举的那些例子一样。
(顺带说一下。我经常看到,一个网站中,很多人非SEO的人员,如工程师和网页设计人员或者网站编辑,都以为SEO和他们做的事情是相反的。这都是因为长期以来一些SEOer经常提交很多明显违反用户体验的SEO需求给他们,造成他们以为SEO就是和他们做的事情是有冲突的。实际上,SEO和别的部门有非常少的冲突,只要你能用科学的方法去实践,就能发现以前有太多误导人的观点了。还有,对于其他部门的专业人员,他们专业领域的意见非常值得去考虑。)
爬虫有一个特点,就是它不能实时的比较它正在抓取的内容是不是重复的内容。因为如果要做到实时的比较,那它至少要把正在抓取的页面和那些已经在索引库的页面做对比,这是不可能短时间内可以完成的。 前面把所有URL统一放到一个待抓取列表中的方法只能避免那种URL完全一模一样的重复抓取,但是无法应对URL不一样、但是内容一样的抓取。
正如所有搜索引擎都强调的那样,动态参数是一个经常产生URL不一样、但是内容一样的现象的原因。所以搜索引擎建议大家用静态化的方法去掉那些参数。静态化的本质是URL唯一化,在《优化网站的抓取与收录》这篇文章中,曾经用的“一人一票”这个描述就很贴切的表达了这个意思。静态化只是一个手段而不是目的,为了保证URL的唯一化,可以把URL静态化、也可以用robots.txt或nofollow屏蔽动态内容、可以用rel=canonical属性、还可以在webmaster tool里屏蔽一些参数等等。
而静态化也会有好的静态化和不好的静态化之别。我们这里不说那种把多个参数直接静态化了的案例,而是单纯来看看如下两个URL:
http://www.semyj.com/archives/1097和 http://www.semyj.com?p=1097
这两个URL中,这个静态化的是不是就比动态的好呢? 实际上这两个URL的差别很小。首先这两种URL搜索引擎都能收录,如果说动态URL“?p=1097”可能产生大量重复的内容让爬虫抓取,那这个静态的URL“archives/1097”也不能保证不会产生大量重复的内容。特别是爬虫在抓取时碰到大量有ID的静态的URL时,爬虫无法判断这个网站是不是把session ID等参数静态化了才造成的,还是这个网站本来就有这么多内容。 所以更好的静态化是这样的:
http://www.semyj.com/archives/seo-jingli
这种URL就能保证唯一化而不会和其他情况混淆了,所以URL中要尽量用有意义的字符。这不是因为要在URL增加关键词密度而这么做的,是为了方便搜索引擎抓取。
以上是因为爬虫固有的特点造成的抓取障碍,而有时网站的结构也能造成爬虫的抓取障碍。这种结构在《优化网站的抓取与收录》一文中用的名字是“无限空间”。文中举了一个日历的例子:如很多博客上都会有一个日历,顺着这个日历的日期一直往下点,永远都有链接供你点击的,因为时间是无限的。
其实还有更多的“无限空间”的例子,只是“无限空间”这个名词没怎么翻译好,翻译做“无限循环”就容易理解多了。 举一个例子:
京东商城笔记本分类页面: http://www.360buy.com/products/670-671-672-0-0-0-0-0-0-0-1-1-1.html

筛选条件
当点击“惠普”+“11英寸”这2个条件后能出来一个页面,点击“联想”+“14英寸”+“独立显卡”也能出来一个页面。那总共能出来的页面有多少呢?
这个页面中,品牌有18个分类、价格9个分类、尺寸7个分类、平台3个分类、显卡2个分类。 那么可以组合成的URL个数为:
按1个条件筛选: 18+9+7+3+2 = 39 。
按2个条件筛选:18×9+18×7+18×3+18×2+9×7+9×3+9×2+7×3+7×2+3×2=527 。
按3个条件筛选:18×9×7+18×9×3+18×9×2+18×7×3+18×7×2+18×3×2+9×7×3+9×7×2+9×3×2+7×3×2=3093。
按4个条件筛选:18×9×7×3+18×9×7×2+18×7×3×2+18×9×3×2+9×7×3×2=7776。
按5个条件筛选:18×9×7×3×2=6804。
总共可以组合出的URL数量为:39+527+3093+7776+6804=18239 个。
笔记本分类里总共才 624个商品,要放在18239个页面中,而有的页面,一个页面就能放32个产品。势必造成大量的页面是没有商品的。如点击这几个筛选条件后,就没有匹配的商品出来了:

无结果
这样的结果,就是造成大量重复的内容以及消耗爬虫很多不必要的时间,这也可以认为是“无限空间”。 这类情况非常常见。如

某房产网的无限空间
上面举的京东商城的例子还是不怎么严重的,有的网站能组合出几亿甚至无穷无尽个URL出来。我在国内和国外看过那么多同类的网站,居然发现迄今为止只有两家网站注意到了这个问题。究其原因,还是因为很多SEO人员不太重视数据,这种问题稍微分析爬虫的日志就可以看出来的。直到现在,还有一些SEOer认为把这些以前是动态的页面静态化是个有积极意义的事情,没看到不好的一面就是这样的动作制造出了大量重复的页面,向来就是一个在SEO方面不好的改动。
文章来源:http://www.semyj.com/archives/1136
免责声明:本站资源来自互联网收集,仅供用于学习和交流,请遵循相关法律法规,本站一切资源不代表本站立场,如有侵权、后门、不妥请联系本站删除!
这一波大模型产业落地浪潮里,不少企业其实处在 “干瞪眼“的状态。
一种情况是,很多大模型产品看得见却摸不着,在台上一个个遥遥领先——今天Sora技精四座,明天英伟达的机器人又赢得满堂彩,可是到了台下一问:啥时候能用上啊?答曰:遥遥无期。
另一种情况是,企业想用上大模型,却又难免瞻前顾后——既要考虑场景融合,又得兼顾安全性,还要考虑打通现有系统,再加上各种部署成本和繁琐的采购流程……最后只能拂袖:罢了,再等等吧。
稳了!魔兽国服回归的3条重磅消息!官宣时间再确认!
昨天有一位朋友在大神群里分享,自己亚服账号被封号之后居然弹出了国服的封号信息对话框。
这里面让他访问的是一个国服的战网网址,com.cn和后面的zh都非常明白地表明这就是国服战网。
而他在复制这个网址并且进行登录之后,确实是网易的网址,也就是我们熟悉的停服之后国服发布的暴雪游戏产品运营到期开放退款的说明。这是一件比较奇怪的事情,因为以前都没有出现这样的情况,现在突然提示跳转到国服战网的网址,是不是说明了简体中文客户端已经开始进行更新了呢?