#1 从博客上复制内容:

上图是主要针对博客这种网站媒体类型的,我们使用wordpress的时候经常将文章毫无保留地展示在首页,而不是使用输出摘要(就好像SEMWATCH那样),根据Randfish观察,其实这样子是会搜索引擎误认为内容重复。
#2 URL参数引起的内容重复

究竟URL参数像Session IDs,Tracking IDs是怎样引起内容重复的呢?Googlewebmastercentral (需要翻墙) 透露,同一个产品页面,如果搜索引擎爬虫抓取可以通过多种链接途径抓取同一个产品页面,那样会有以下几种消极的影响:
1.多种URLs会稀释链接的广泛性。比如上图的产品页面,如果有50个导入链接,那有可能分别形成了3种导入URL途径,而不是唯一的某一个URL,这样就等于将导入链接传递的权重分散到3个不同的链接上。
2.搜索结果或许会呈现不友好的URL(比如一大串长长 的session ID,tracking ID)。从而在SERP中,降低了用户对该页面的清晰了解程度(英文url比如semwatch.org/sem,不仅仅具备搜索引擎友好性,更重要的是用户体验友好性),不利于品牌的塑造。
#3 搜索引擎对待内容重复的态度
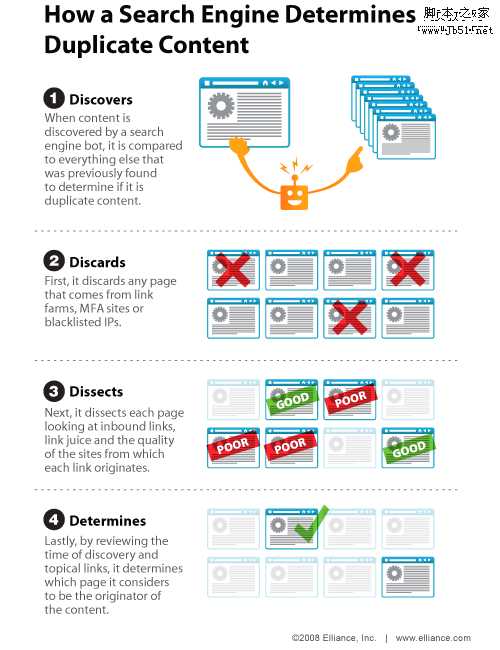
从Search Engine Land给出上图可知,一般来说搜索引擎通过4个步骤来识别内容是原创还是复制:
1.发现。当搜索引擎爬虫发现新的内容,他会立刻与之前收录的内容进行比较确保内容的原创性。
2.丢弃。首先,搜索引擎会放弃收录那些来自链接工厂,MFA站点(Made For Adense)和被列入黑名单的IP的页面
3.解剖。下一步就是分析每个页面的 入站链接,判断链接的质量和源头。
4.决定。最后就是回顾之前收录的页面和相关链接,决定哪一个页面才是绝对原创。
#4 关键词拆解

搜索引擎会蜘蛛通过你的某一个特定页面爬行4个或者40个网站上不同的页面,而这种行为一般是通过该页面的相关内容链接进行爬行抓取(比如上图的“滑雪板),很多朋友希望通过将众多页面相互关联起来即使相互之前没有关联性,一个站点的许多页面过度使用同一个关键词,从而为了提高排名。但是事实上,这种行为对于排名是帮助不大的。
#5 怎样处理好内容重复的情况
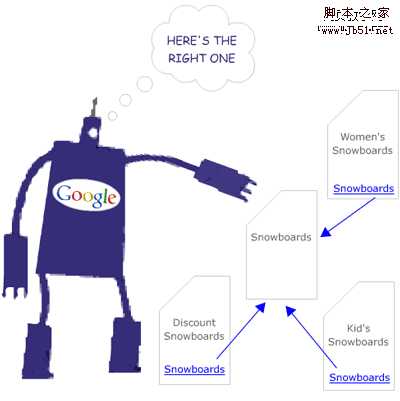
这里不同在于不是仅仅通过“滑雪板”这个词而是通过各种各样,有价值而且唯一的关键词(比如折扣滑雪板,小孩滑雪板等)链接到原来的内容上。这样搜索引擎就可以很容易确定该页面与其他页面的相关性极强,这不仅仅基于搜索引擎友好性,更是考虑到用户体验与网站未来的信息架构。
Canonical标签
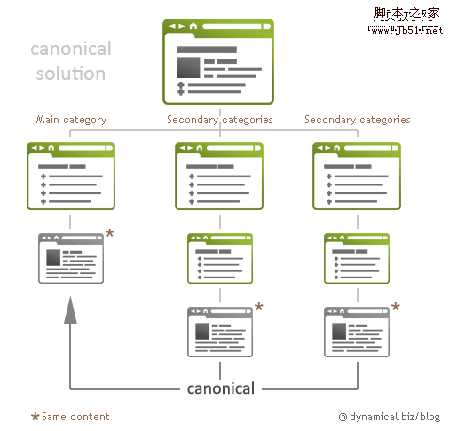
Source: Dynamical.biz
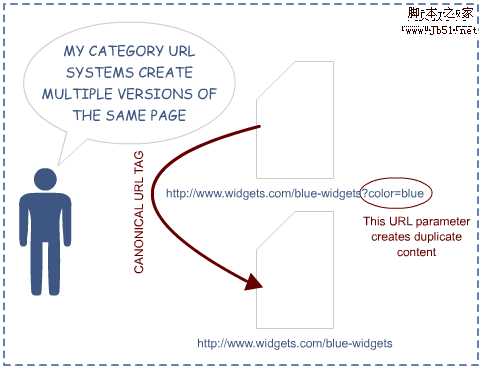
Source: SEOmoz.org
其实上面两幅图都涉及到一个问题,那就是网址规范化,针对这个问题,Zac前辈很早前就给我们分析过—网址规范化问题最新解决方法,大家可以前往学习。
301重定向
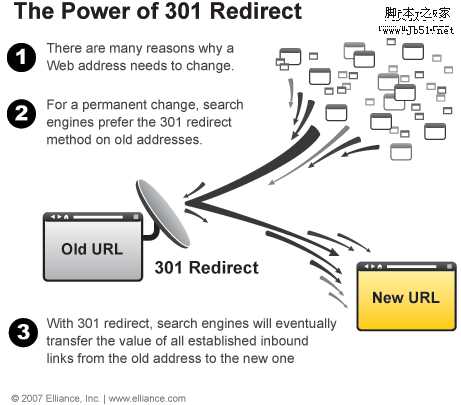
301重定向也是解决内容重复的重要方法,对于永久的重定向,搜索引擎更偏爱于301重定向。随着301重定向实施,旧网站的权重就会自动传递到新的网站上。
当各位了解了搜索引擎对于内容重复判断机制以后,相信对各位的优化工作会有所帮助。我们经常说“细节制胜”,所以无论是网络营销还是单纯的SEM都必须遵循这样的一个原则和细节,方能制胜。
图表收集:Ann Smarty,原文链接 本文首发 SEM Watch ,转载请注明出处
免责声明:本站资源来自互联网收集,仅供用于学习和交流,请遵循相关法律法规,本站一切资源不代表本站立场,如有侵权、后门、不妥请联系本站删除!
这一波大模型产业落地浪潮里,不少企业其实处在 “干瞪眼“的状态。
一种情况是,很多大模型产品看得见却摸不着,在台上一个个遥遥领先——今天Sora技精四座,明天英伟达的机器人又赢得满堂彩,可是到了台下一问:啥时候能用上啊?答曰:遥遥无期。
另一种情况是,企业想用上大模型,却又难免瞻前顾后——既要考虑场景融合,又得兼顾安全性,还要考虑打通现有系统,再加上各种部署成本和繁琐的采购流程……最后只能拂袖:罢了,再等等吧。
稳了!魔兽国服回归的3条重磅消息!官宣时间再确认!
昨天有一位朋友在大神群里分享,自己亚服账号被封号之后居然弹出了国服的封号信息对话框。
这里面让他访问的是一个国服的战网网址,com.cn和后面的zh都非常明白地表明这就是国服战网。
而他在复制这个网址并且进行登录之后,确实是网易的网址,也就是我们熟悉的停服之后国服发布的暴雪游戏产品运营到期开放退款的说明。这是一件比较奇怪的事情,因为以前都没有出现这样的情况,现在突然提示跳转到国服战网的网址,是不是说明了简体中文客户端已经开始进行更新了呢?